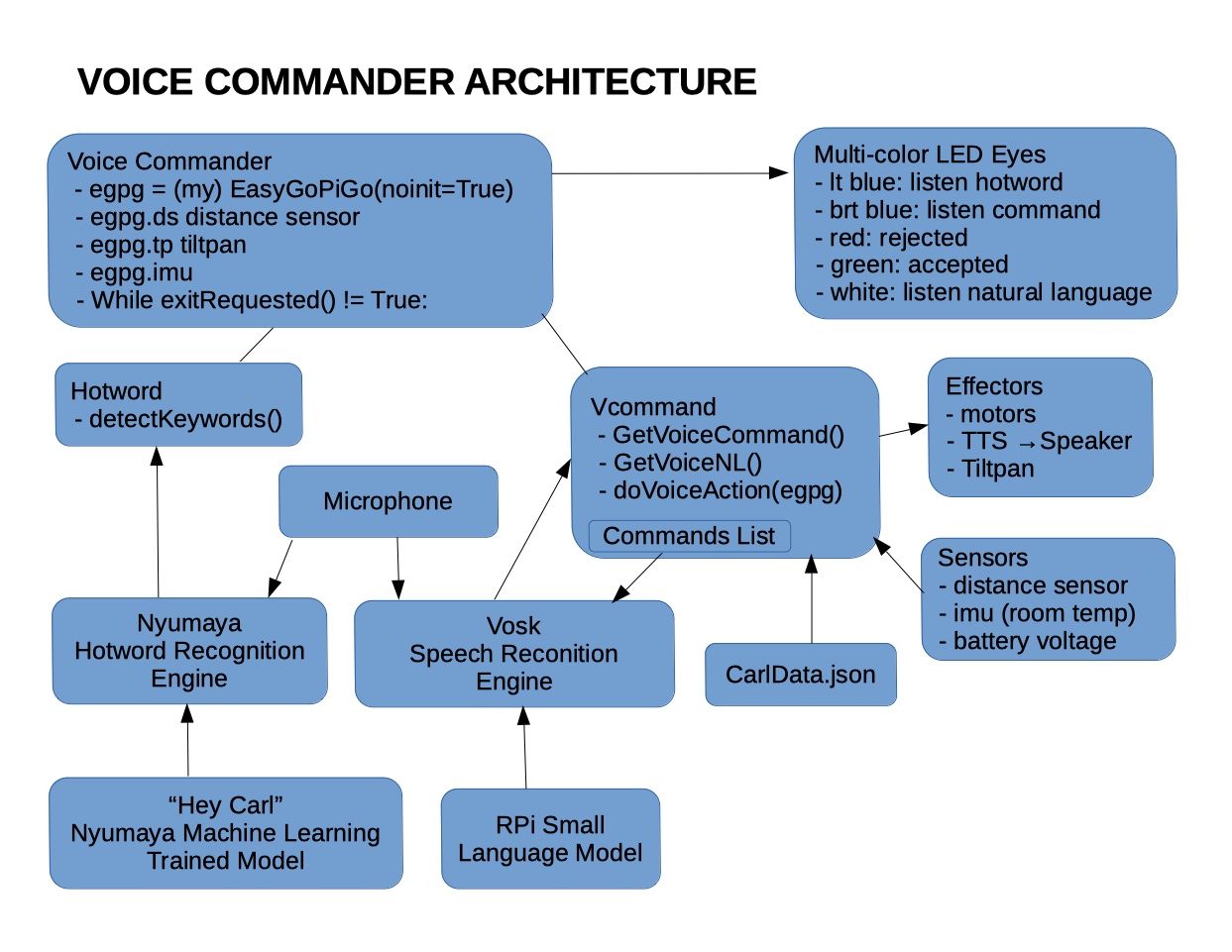
What do you get when you run two machine learning trained speech recognition engines on a Raspberry Pi 3B?
FUN!
Warning - the video is 4 minutes long, but Carl wants you to know all the details:

What do you get when you run two machine learning trained speech recognition engines on a Raspberry Pi 3B?
FUN!
Warning - the video is 4 minutes long, but Carl wants you to know all the details:
Wow - really cool
/K
PS - love the squirrel
Totally impressive!
One day Charlie hopes to do that.
Looks like you’ve solved the lion’s share of the speech issues. Good job!
Looking at this again, there is more to this than meets the eye and the accomplishment is greater than casual inspection would lead you to believe.
Getting ONE speech engine working on the Pi that doesn’t require huge amounts of cloud processing and doesn’t have a hard dependency on a network connection is a HUGE accomplishment.
Doing that without consuming every processing resource the Pi has is an even greater accomplishment.
But the real kicker is getting two ENTIRELY DIFFERENT speech engines on the same Pi to PLAY NICE and NOT CRASH is an even higher-order accomplishment.
Quite frankly, I’m impressed. Even more than impressed - astonished - that this was not only doable, but doable with a reasonably high level of speech and word acceptance without a hard requirement for off-system cloud resources.
Bravo!
Next challenge: Walking on water.
Exactly.
I’m really pleased with and excited about the result. Carl was deaf for over two years - Doing his own thing, not really able to interact with anyone other than me. This new interface modality will open up his “presence.”
For the last two years, I often found myself walking to our “office”, sitting down, waking my computer, typing my password (or lately my watch logs me in), browsing to the RPI-Monitor to see Carl’s “health”, and then going back to whatever I was doing.
Now, I can interact with him from the living room couch in the adjoining room, or just walking by the office and speaking “Hey Carl, swap space?” or “Hey Carl, battery voltage?”
I can whisper it and he hears me. I can even speak to him while my wife is blow drying her hair, albeit not in a whisper, but Carl usually gets what I am saying the first time.
The responsibility now is to teach Carl to dialog … about himself, of course, but also common expectations of courtesy, like responding to greetings.
Every few minutes, I think of another exchange I need to program. It is like starting all over to add functions to Carl.
. . . to boldly go where no GoPiGo has gone before!
You’ve now opened up whole new vistas - not just for the GoPiGo, but for the Pi in general. You should seriously consider writing a posting on the Raspberry Pi forum about your research and accomplishments. This could be very, very interesting and valuable for a lot of people.
I have one of Google’s “AIY” kits - an Alexa clone - that requires an account on Google’s dev site - and costs money! to render even acceptable speech.
You’ve opened the possibility of my resurrecting that beastie and actually making it do something useful.
Yet another thing for my long list of projects. . . 
Update:
You should consider a non-RFR version on a bare Pi so that the rest of us will know how to use it in a non-robotics environment.
I also have a first gen Google Voice AIY kit sitting non-functional on my desk. Google APIs changed, and Google changed the AIY voice kit hardware a little bit so the latest kit software does not run on first gen kits.
The dual far-field microphone is probably the most salvageable part, although I did notice that the Voice kit main board has holes for servo connections, such that it might be possible to add two motors and a skid ball to have a walking, talking, “hey google” bot.
Given that we have GoPiGo3 bots, these AIY voice kits are likely doomed to sit as technology antiques on the desk.
It takes about 15 minutes to install both engines and try the examples. No luck, no skill, just follow below:
For the Nyumaya Hotword Engine, Anyone can run the examples to wake up to “Marvin”, “Sheila”, “Alexa”, or “Hey Google”
curl -L0 --output x.zip https://github.com/nyumaya/nyumaya_audio_recognition/archive/master.zip
unzip x.zip
cd nyumaya_audio_recognition/examples/python
python3 simple_hotword.py
Do the following for Vosk Speech Recognition “SDK” and you will be talking to your raspberry pi with command lists, natural language, or performing speaker identification.
$ pip3 install vosk
.
Successfully installed vosk-0.3.15
Alpha Cephai says “Vosk requires libgfortran on some Linux builds which might be missing, you might need to install libgfortran”
(yes, indeed else get ImportError: libgfortran.so.3: cannot open shared object file: No such file or directory)
$ sudo apt-get install libgfortran3
See https://alphacephei.com/vosk/models for all models available
$ mkdir models
$ curl -L0 --output models/vosk-model-small-en-us-0.15.zip http://alphacephei.com/vosk/models/vosk-model-small-en-us-0.15.zip
$ cd models
$ unzip vosk*.zip
See https://alphacephei.com/vosk/models
$ curl -L0 --output models/vosk-model-spk.zip https://alphacephei.com/vosk/models/vosk-model-spk-0.4.zip
$ cd models
$ unzip vosk-model-spk*.zip
See https://github.com/alphacep/vosk-api
$ mkdir vosk-api
$ curl -L0 --output vosk-api/vosk-api.zip https://github.com/alphacep/vosk-api/archive/master.zip
cd vosk-api
unzip vosk-api.zip
cp vosk-api-master/python .
rm -rf vosk-api.zip vosk-api-master/
$ cd ~/Carl/Examples/Vosk/vosk-api/python/example
$ ln -s ../../../models/vosk-model-small-en-us-0.15/ model
$ time ./test_simple.py test.wav
.
"text" : "one zero zero zero one" ( source: "1 0 0 0 1" )
.
"text" : "nah no to i know" ( source: "9 oh 2 1 oh" )
.
"text" : "zero one eight zero three" (source: "0 1 8 0 3" )
real 0m15.933s
user 0m15.563s
sys 0m0.720s
Right now, the AIY kit is the only thing I have with a speaker and microphones. As it’s not committed to any other task - like being a robot - it’s a prime choice for any stand-alone speech experimentation I might want to do.
The only kicker is if the software can find the microphones and the speaker interfaces on the sound hat in the AIY kit.
BTW, is there a way - make that, have you heard of a way - to tell a first generation AIY kit from later versions? Except for the fact that I bought it a year or two ago, I wouldn’t know what generation it is without trying the latest software on it.
P.S.
One of the things that really burns my biscuits is the fact that 99% of the interesting hats all use the SPI buss, and none of them consider the fact that other things might want to use SPI too. They are set up as a master - single slave setup that does not use either of the two “chip select” SPI pins to identify which of many slave devices are being addressed. I’m not even sure if the GoPiGo controller uses the chip-select pins. (I’d have to dig up the schematic again. . .)
Ergo, if you want to use more than one device that depends on SPI - yer’ hosed - even though with two chip select pins available you could address a maximum of three devices, assuming that 0x00 means nothing is selected.
If your kit came with a Pi-Zero it is the new version, if not and you built it with a RPi3B then it is the early version.
Current/Newer kit instructions: https://aiyprojects.withgoogle.com/voice/
Perhaps I am wrong about the software not working - Google has instructions (and code) for the older kit here:
That settles it - I’ve got a dinosaur, though I’m not sure I’d like to try any real-time voice recognition software on a 'Zero. I might as well pop a Pi-1 in there.
Yep - I’ve got a voice kit and a vision kit with a light coating of dust on the back corner of my computer desk. Just not enough hours in the day…
/K
Vision kit? What vision kit?
Rats! That would be fun to play with.
The only reason I gave up on the voice kit was that customization options were extremely limited without connecting to Google. Not to mention the only time you got a voice that didn’t sound like a cat being strangled was with the Google supplied data. Stand-alone, it was awful.
Re: Vision kit.
Never heard of it, and never saw it. All I’ve seen were crates and crates of the voice kit at Micro Center.
You want to send that vision kit to me, I’ll send you my address!
Quite frankly, I’m all on fire to try @cyclicalobsessive’s technique for voice. If I can get my voice kit to do one third the stuff Carl can do right now, I’ll be a Happy Bunny!
https://aiyprojects.withgoogle.com/vision
I’ve just started an online course on using OpenCV - I’m hoping to get more into computer vision with my robot. At the very least I can savage the Pi and Camera from this.
/K