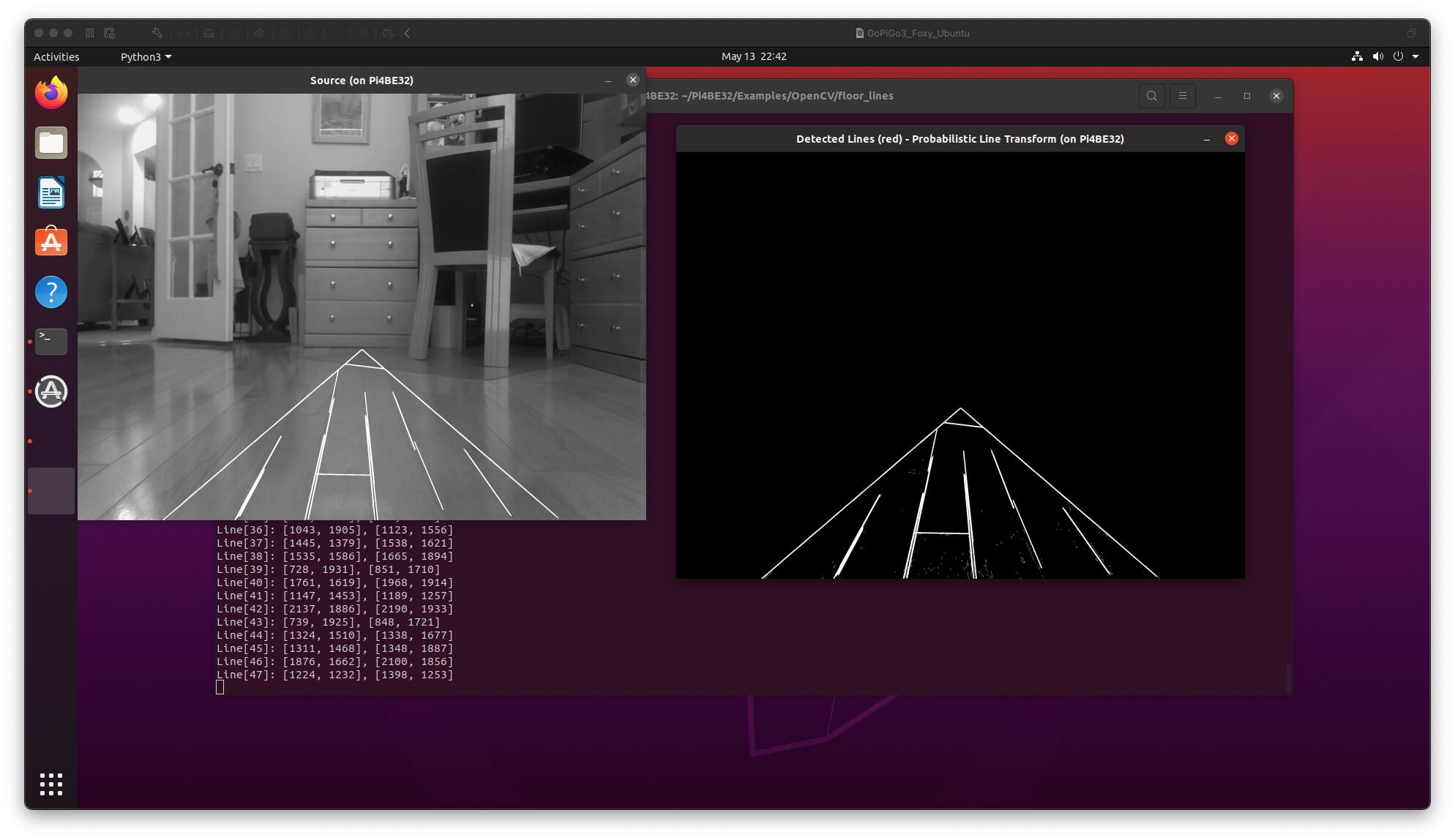
It looks interesting - lane following the cracks on the floor? If that’s the case, where does the triangle come in? That’s not aligned with the floorboards.
Though it looks interesting and clever, you will have to provide a bit more detail for a thick-headed oaf like me to understand the significance of what I’m looking at.
The idea is to follow the cracks in the floor, or the cracks/grout in the floor tiles.
Process right now is:
convert image to grayscale
blur it a little
mask to area immediately in front of the bot
compute thresholds for edge detection
perform canny edge detection
find probable lines on unmasked detected edges
then figure out:
7) the closest, most nearly vertical line
8) direction to drive to be “on” the line
9) direction to drive to stay on the line
I should add that the image tested is 1092 x 819. I need to test resizing the image to 320x240 or capturing at that resolution to see if I can speed up the process without hurting the line detection.
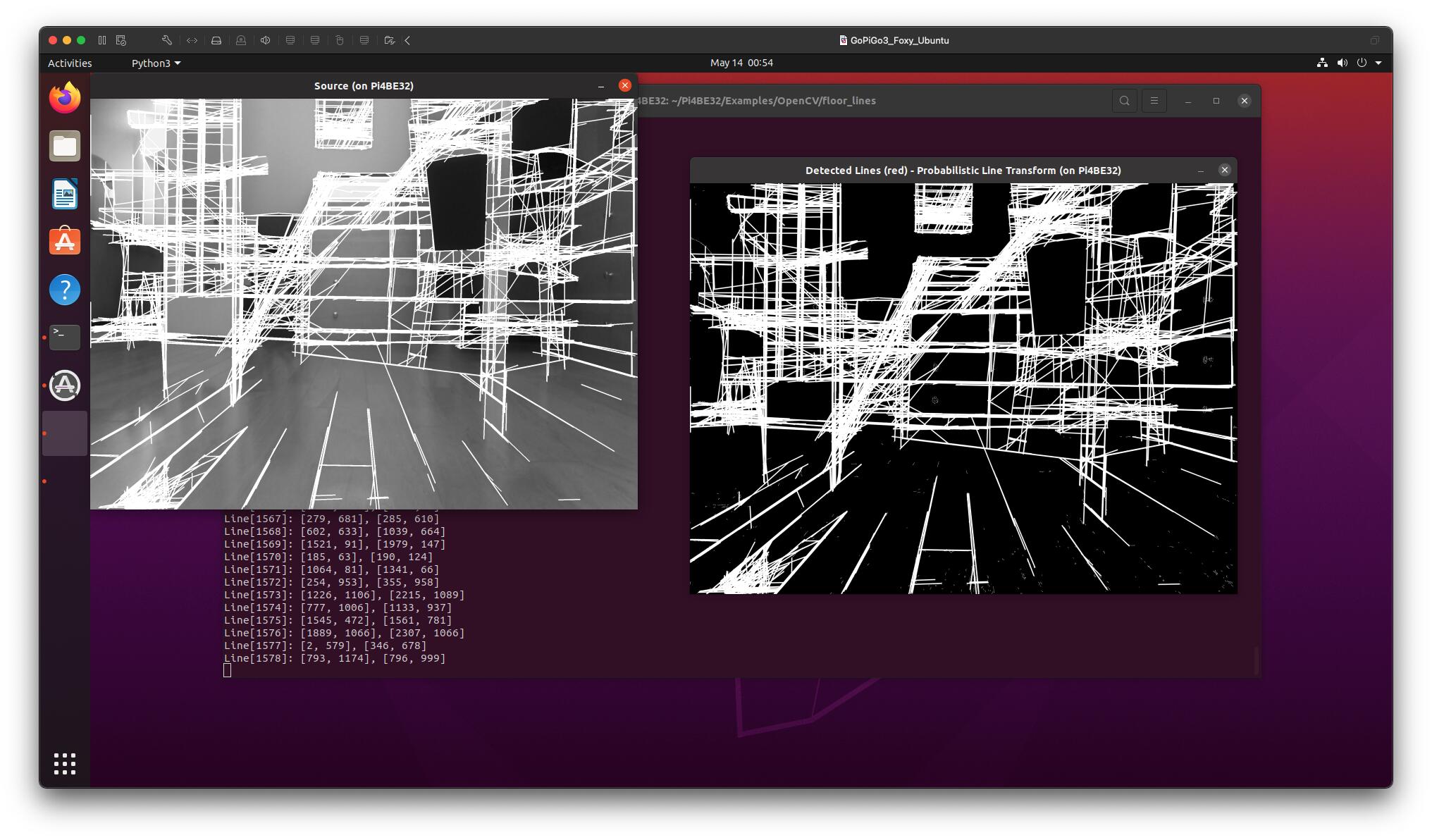
This is what it would look like if I didn’t mask to the area in front of the bot:
That is a lot of unnecessary processing that would slow finding the one line to follow.
This will be a special case of “line following” for straight segments. General line following tends to use a different algorithm but this is what came to mind with the OpenCV skills I have. Probably should have done some research instead of jumping into “code slinging”.
That compute thresholds step is also going to be an area of research as lighting, colors, and contrast vary as the bot moves and the house lights come on and off. This may be the most challenging thing to figure out.
The triangle is an artifact of the edge of the masked area to the unmasked area.
I mask the image to only have data within the triangular area 15% at bottom left and right to 40% up from the bottom. This is called the ROI region of interest (hoping for an ROI - return on investment of computation).
I remember that life - 12 hour days at work and 18 hour days on the weekend working on the new home. I feel it ended up worth the sacrifices in my case.
I often have to remind myself that I shouldn’t put pressure on myself about Carl and Dave. Never the less, after hearing me excited at a little progress, my wife will ask “When is Dave going to do something? You said ROS was going to allow him to use other people’s code.” … And everyone I meet, after hearing I build robots, asks “What do they do?” I used to say “we’ll find out after I retire”; Now I’m looking for a new excuse for my and my robots’ inadequacies.
It probably doesn’t take much “line following” to drive in a straight line. egpg.forward()
Subconscious to this has been the idea that there is a straight floor board crack lined up with Carl’s dock that should be useful to help Carl to return to his dock. That is the actual significance of enabling Carl with “line following”
Have you considered the possibility of a distinctive mark or line extending to the dock? (i.e. a strip of black electrical tape, etc.) Perhaps a beacon of some kind?
IOW, some kind of distinctive way for Carl to:
Recognize HIS dock, (as opposed to Dave’s dock).
Using the visual cues you’re working on, identify exactly when he’s directly in front of the dock.
Follow the visual cues to a point where he can turn around and dock himself.
One thought I just had was a line containing a series of marks:
Viz.: One white line, then two white lines close together, then three white lines close together. If the succession of lines is “1, 2, 3”, then he’s headed in the correct direction.
You are not going to be able to do this purely in software unless you can find a way to get a Pi-3 to recognize “dock”, (as opposed to “face” or “cup”), and move toward it.
I think the issue was Carl needed to be quite close before recognizing the codes. There was some trade off on resolution versus distance that gave me pause on this approach, but I don’t remember specifically. (Two years ago - wow. I abandoned Carl’s dream.)