The GoPiGo OS has a mobilenet object recognition TensorFlow lite demo using the PiCamera on the GoPiGo3.
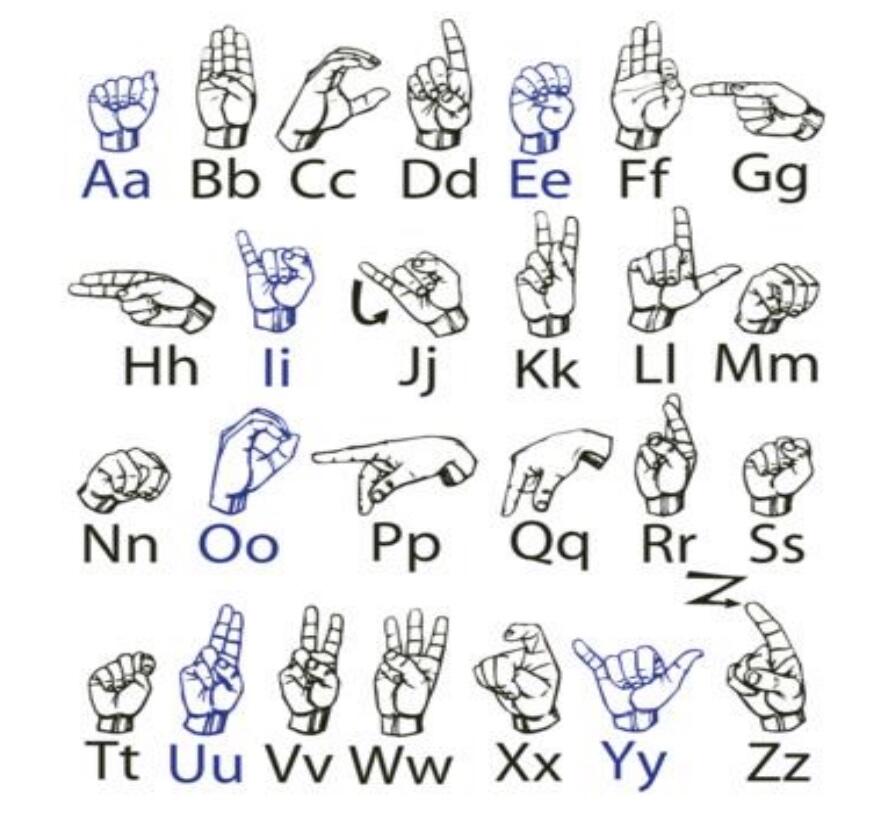
Anyone know if there is a TFlite model that recognizes American Sign Language spelling? Recognizing ASL words or phrases would involve multi-frame recognition, but almost all of the letter signs are static hand positions. I think maybe only “J” and “z” involve motion.
No where fast…can’t install TFlite on Ubuntu 22.04 64-bit for some reason.
Resetting to re-familiarize myself with GoPiGo OS 3.0.3 that already has TFlite installed.
That is probably the most useful to everyone else if I can get a demo working anyway. I had trouble setting up GoPiGo OS to my network last time I tried it, so I thought I would try with Dave’s current OS first.
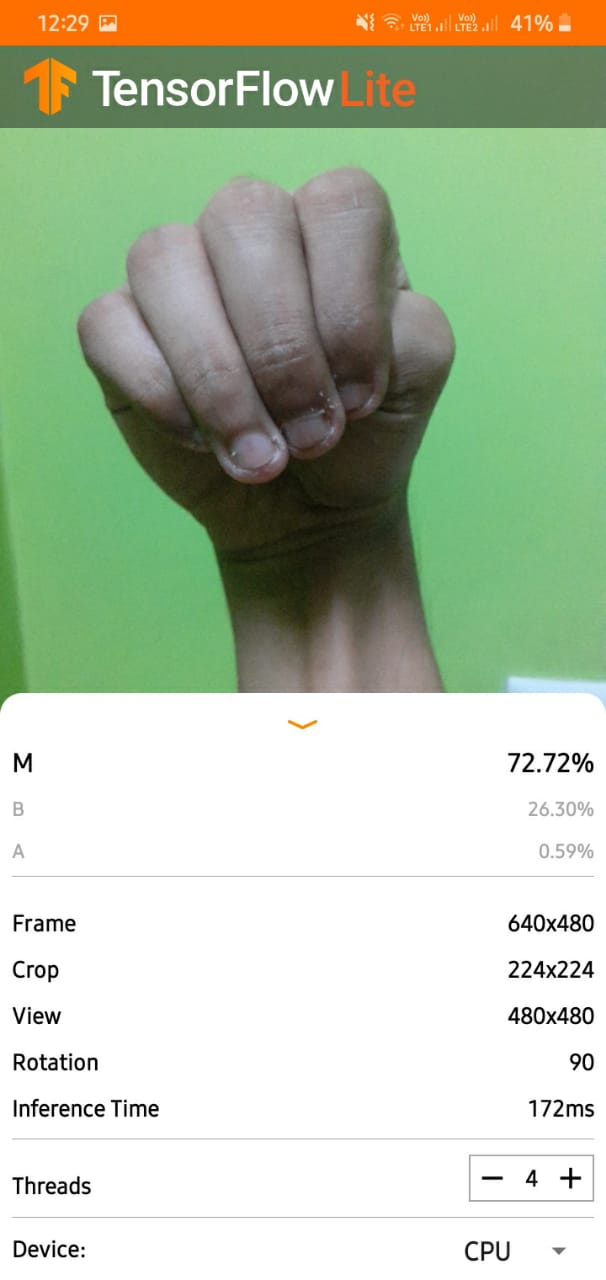
Tested the existing tflite classify_picamera example on Dave (which has 180 rotated camera images) - works on an “electric fan” and a “monitor” but fails to recognize my scissors for some reason.
So on to try ASL!
Initial thrill - it loads the model and labels without complaint.
It recognizes “nothing” very well.
Everything else comes out as “C”, and I mean everything.
I don’t know how to view a preview with the GoPiGo OS, so debugging will be a bit difficult.
This test seems to suggest success is possible.
TensorFlowLite on GoPiGo OS
1) Connect GoPiGo OS to WiFi for convenience
2) Bring Down ASL model and label file
- su jupyter (password: jupyter)
- cd tflite/tflite_models
- sudo curl -o labels_ASL.txt https://raw.githubusercontent.com/sayannath/American-Sign-Language-Detection/master/ASL%20App/app/src/main/assets/labels.txt
- sudo curl -o ASL.tflite https://raw.githubusercontent.com/sayannath/American-Sign-Language-Detection/master/ASL%20App/app/src/main/assets/model.tflite
python3 /home/jupyter/tflite/tflite_examples/lite/examples/image_classification/raspberry_pi/classify_picamera.py \
--model /home/jupyter/tflite/tflite_models/ASL.tflite \
--labels /home/jupyter/tflite/tflite_models/labels_ASL.txt \
--preview no \
--confidence 0.7
Dave's camera is rotated 180 so needed to add:
try:
camera.rotation=180 <----
stream = io.BytesIO()
- Made a copy with the change called asl_picamera.py in /home/jupyter/tflite
Running asl model:
python3 /home/jupyter/tflite/asl_picamera.py \
--model /home/jupyter/tflite/tflite_models/ASL.tflite \
--labels /home/jupyter/tflite/tflite_models/labels_ASL.txt \
--preview no --confidence 0.7
Running classify model:
python3 /home/jupyter/tflite/asl_picamera.py \
--model /home/jupyter/tflite/tflite_models/mobilenet_v1_1.0_224_quant.tflite \
--labels /home/jupyter/tflite/tflite_models/labels_mobilenet_quant_v1_224.txt \
--preview no --confidence 0.7
Carl came to the rescue - he is also set up to run TFlite and has a desktop (Raspbian4Robots). Carl saves the images that he classifies and I can look at them on Carl’s desktop.
pi@Carl:~/Carl/Examples/TF/GoPiGo $ ./run_asl.sh
Starting TensorFlow Lite Classification With PiCamera at 640x480
C 0.62 289.2ms
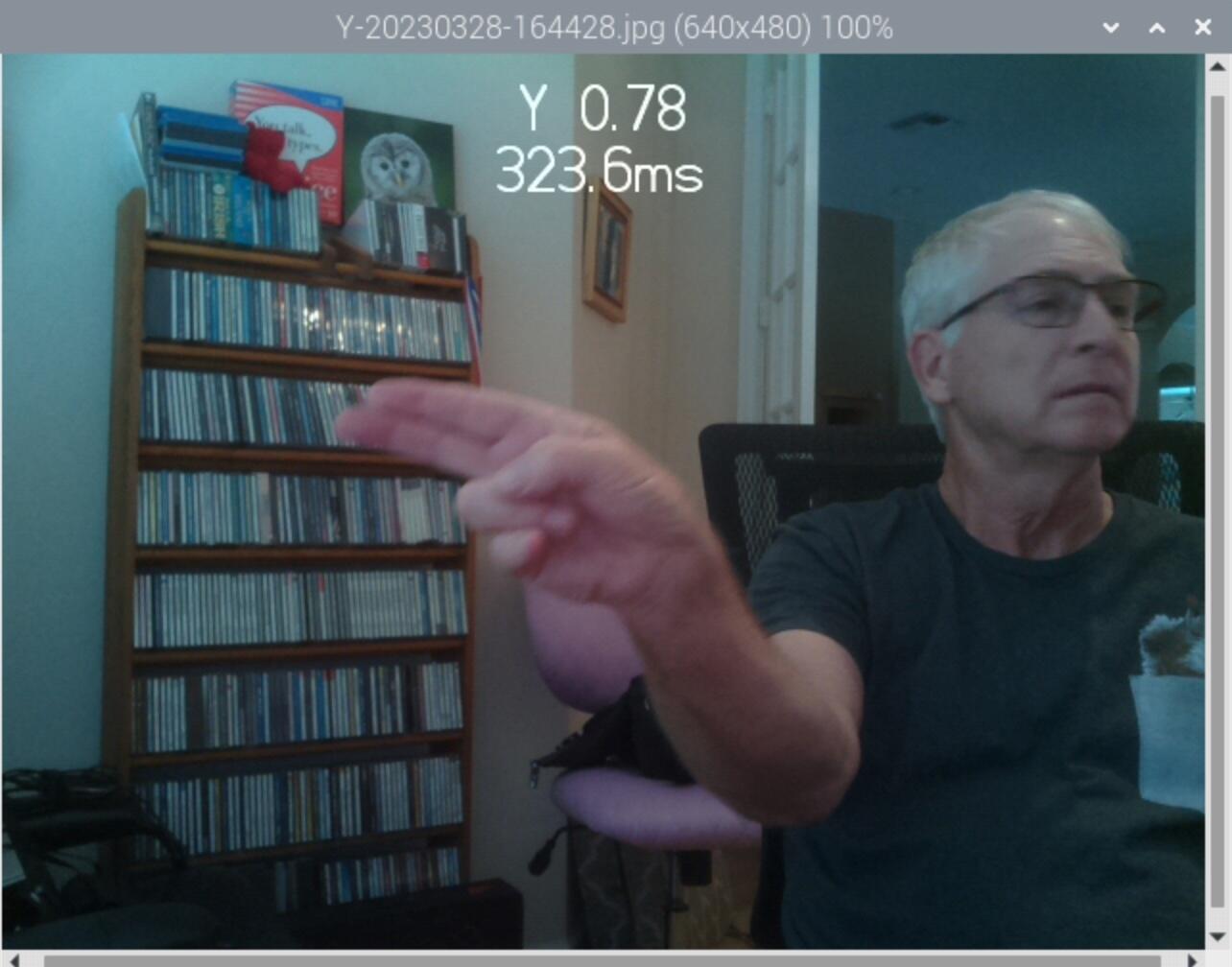
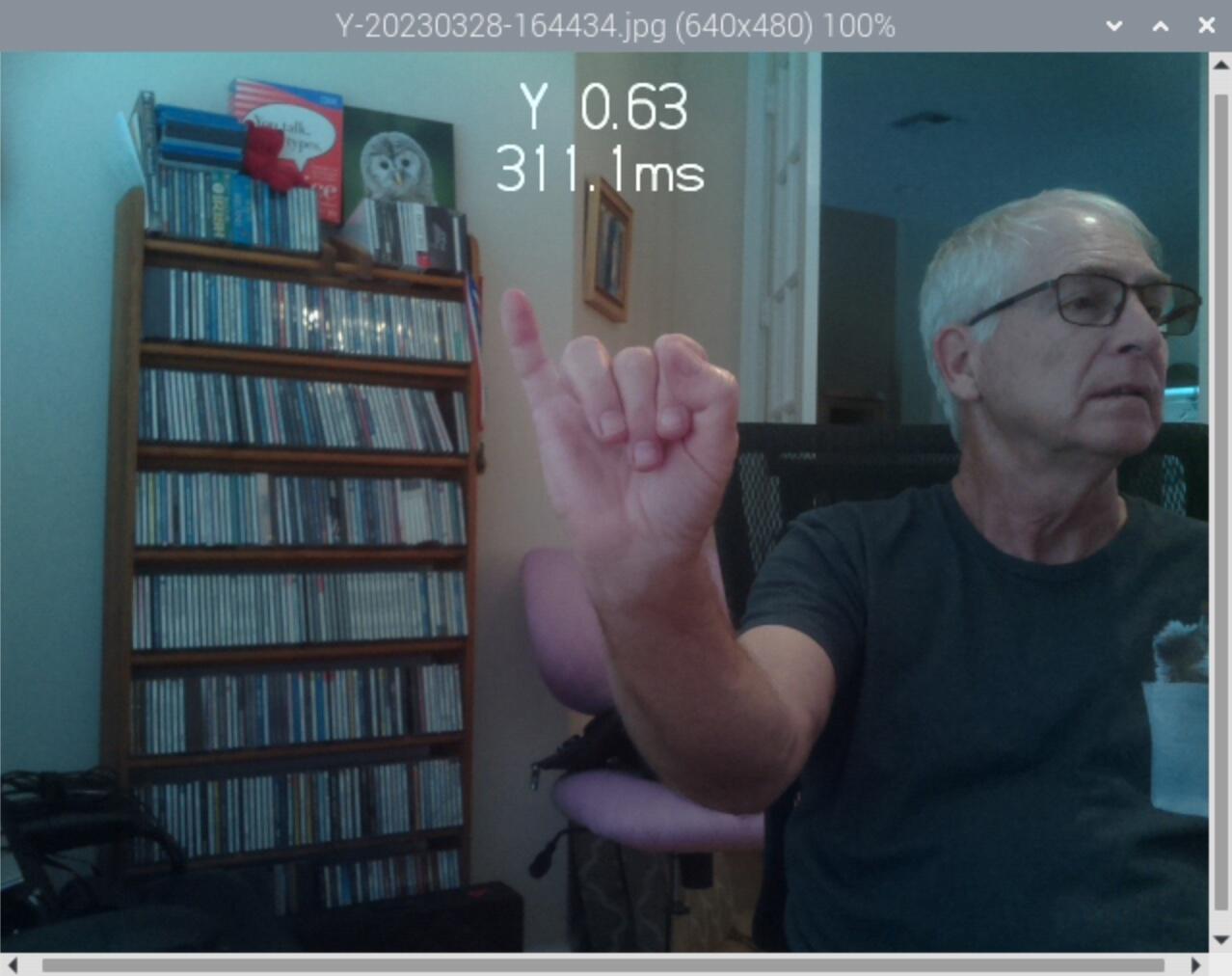
Y 0.61 316.3ms
C 0.74 306.4ms
C 0.84 325.5ms
C 0.65 303.1ms
C 0.90 293.1ms
C 0.64 341.8ms
C 0.61 312.4ms
Y 0.68 313.9ms
Y 0.71 325.2ms
Y 0.81 293.3ms
C 0.91 323.4ms
C 0.97 289.7ms
Here are the images and confidently wrong classifications:
This is pretty cool even though not correct classification, because Carl is sporting a Pi3B+ so it shows the stock GoPiGo3 running TFlite can do three classifications per second (if I can figure out why it is so confidently wrong…)
Wow, that really is confidently wrong. Can you tell it to also give the second and third most likely guesses? That might be interesting. None of the guesses you showed are all that high a probability.
/K
In the demo image, it shows “Frame, Crop, View” parameters with “Crop 224x224” and in the Mobilenet doc it mentions this dimension “Our primary network (width multiplier 1, 224 × 224),” but elsewhere in the doc it mentions the input as 320x320: "Both MobileNet models are trained and evaluated with … The input resolution of both models is 320 ×
320. "
I don’t know if they are using a segmentation step to “find a hand” and then apply a crop of 3202 or 2242 around “the hand”, but it seems like I need to, at a minimum, try cropping out the center 3202 of the picamera’s 640x480 image and see what happens.
But the actual ASL doc states " The model takes an input image of size 224x224 with three channels per pixel (RGB - Red Green Blue)." Perhaps I will have to crop out the center 2242 of the image, but without a preview on the GoPiGo3, it will be impossible to know when your hand is in the proper position.
Oh yeah, Carl does allow preview - just tested that. GoPiGo OS example may not be possible but if I can figure this out - Carl will be an ASL star!
Argh - closing the ASL program while Carl in on his dock fools the charger into thinking it should switch to trickle charge mode. Carl detects this early trickle, stating “Getting off the dock. I need a real charge”, and then quickly re-docks.
No problem there is an example in the picamera docs, oops, that only works with Python2.7.
No problem there is a Python3.7 example in the latest picamera docs, oops, that only works with picamera 1.14 which will not be released… now there is picamera2
The GoPiGo3 MobileNet TFlite example captures a 640x480 image,
and performs a “resize((width, height), ANTIALIAS)” to the Mobilenet input shape.
When I checked the Mobilenet input shape, it returns 224, 224 same as the ASL model returns - that would seem good.
Thinking about the program and the resize again - there is an interesting thing happening. The image is captured in a 4:3 aspect and resized to 1:1 aspect. The resize means the entire captured image is fed to the mobilenet model, but the subject of the image will be asymmetrically resized. (I think.)
I think what I need to do is crop the 640x480 image to 480x480, then resize with antialiasing to 224x224. If I simply crop the 224x224 out of the center of the image, the user must blindly find the exact center of the camera’s field of view and guess how far away to be to fill the 2242 area to the max. By cropping to 4802 first, the “I see your hand completely” box is twice as big perhaps making the distance from the camera less sensitive.
Now if Carl will be a good boy and get off his dock so I can resume testing…
if hand bounding box has any dimension larger than the ASL model input size,
Perform square CROP of max bounding box dimension,
then RESIZE with anti-aliasing to model input size
else if bounding box is less than ASL model,
then CROP around hand to model input size.
But first I have to prove the ASL model even works (very suspect at this point),
and I’m running into all sorts of “weird ether” issues.
First my very old bluetooth chicklet keyboard issues made me quit everything last night.
Then with a wired keyboard, I got going again this morning until Carl started flashing his “Hey, I’ve got a problem here” LED. life.log showed I2C Bus Failure Detected!
I did a restart, (forgetting that only a cold boot will clear an I2C Bus failure), and the dreaded flashing LED returned.
Then a shutdown and startup cleared the I2C issue, but caused an early trickle that I didn’t notice so Carl got off the dock early.
2023-03-30 09:34|[healthCheck.py.main]I2C Bus Failure Detected
2023-03-30 09:34|[healthCheck.py.main]Initiating 300 second watch for I2C recovery
2023-03-30 09:40|[healthCheck.py.main]I2C not recovered after 300 seconds
2023-03-30 09:44|[logMaintenance.py.main]** Running TFlite killed I2C for some reason, restarting **
2023-03-30 09:45|[logMaintenance.py.main]** Reboot Requested **
2023-03-30 09:45|[logMaintenance.py.main]** 'Current Battery 10.99v EasyGoPiGo3 Reading 10.18v' **
2023-03-30 09:46|[healthCheck.py.main]I2C not recovered after 300 seconds
2023-03-30 09:47|------------ boot ------------
2023-03-30 09:47|[juicer.py.main]---- juicer.py started at 11.00v
2023-03-30 09:49|[healthCheck.py.main]I2C Bus Failure Detected
2023-03-30 09:49|[healthCheck.py.main]Initiating 300 second watch for I2C recovery
2023-03-30 09:55|[healthCheck.py.main]I2C not recovered after 300 seconds
2023-03-30 09:57|[logMaintenance.py.main]** ouch restart doesn't clear I2C failure, need cold boot **
2023-03-30 09:57|[logMaintenance.py.main]** Routine Shutdown **
2023-03-30 09:57|[logMaintenance.py.main]** 'Current Battery 11.91v EasyGoPiGo3 Reading 11.10v' **
2023-03-30 09:59|[healthCheck.py.main]WiFi check failed (8.8.8.8)
2023-03-30 10:02|------------ boot ------------
2023-03-30 10:02|[juicer.py.main]---- juicer.py started at 10.37v
2023-03-30 10:05|[juicer.py.undock]---- Dismount 3672 at 10.3 v after 0.0 h recharge
Between my wife’s huge stream of “new computer acting funny” issues to solve,
and a particularly stealthy “not sharp pictures with some combination of camera/lens/teleconverter between two cameras, two lenses and one teleconverter”,
and my keyboard delete key going bezerk well into a too long editing session,
and Carl declaring an “I2C emergency”,
and those mystery “WiFi check failed” messages in Carl’s log for the last few years,
and my desk is a mess,
and my HOA board is corrupt,
and the country is doomed,
and nature is adapting better than I am,
and …
I’m just not feeling like I have any strength left.
While the research paper reported 98.8% accuracy for the TensorFlowLite ASL running on an Android phone, I cannot get above 0% accuracy for the published model on Raspberry Pi. I am out of ideas and out of my league.